1.minix 1.0 文件系统
在minix1.0中,整个磁盘线性的按照1K大小分成一个一个块,每个块按照不同的作用可以分为统计数据,索引数据和实际数据等。
1.1.数据结构
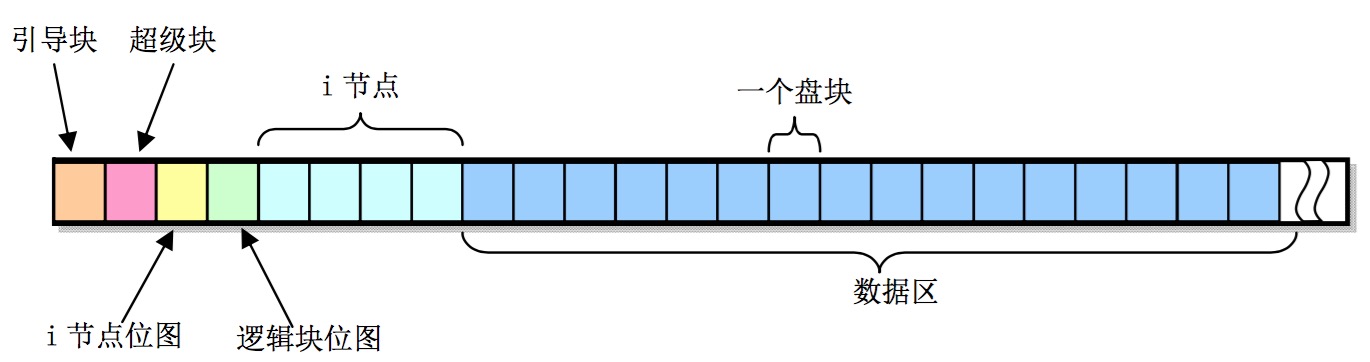
- 引导块:只有作为引导盘的硬盘分区才需要引导块。一般的数据分区引导块内容会空着。
- 超级快: 描述了当前文件分区中的统计数据,例如当前的inode map个数等等。
- i节点位图(imap): inode的索引数据,每个bit代表一个inode,imap最多8块,所以支持的inode最多为1024*8*8=64K,由于一个inode节点数据占用的字节为32byte,所以最多可以支持的inode块数为为1024*8*8*32/1024=2K.这里为每一个i节点编号, 号码从1开始,所以最低为的i节点位图不用(初始化为1),而对应的i节点32字节数据也被初始化为0.
- 逻辑块位图(zmap): 数据块的索引数据,每个bit代表一个数据块,zmap最多8块,所以支持的数据块最多为1024*8*8=64K,支持最大空间为64K*1K=64M。zmap索引数据记录了对于block数据是否可用(被占用)。这里为每一个逻辑块编号, 号码从1开始,所以最低位位图不用(初始化为1)。逻辑号1表示第一个数据区数据,而不是盘上的第一个磁盘块-引导块。数据区的第一个数据块是从编号1开始,而不是0.
- i节点(inode): 记录了每个inode的元数据,例如文件属性,用户属主等,每个inode数据表示一个目录(如/ /usr /usr/local /usr/local/bin等)或者一个文件(如/usr/local/bin/java.exe)。
//inode数据结构,大小为32字节。和imap成线性映射,如第一个imap块支持8192个inode,
//对应的inode1~inode8191按照线性关系存储在inode区。
struct m_inode {
unsigned short i_mode;
unsigned short i_uid;
unsigned long i_size; //记录该节点包含的儿子节点个数(该节点是一个dir节点)
unsigned long i_mtime;
unsigned char i_gid;
unsigned char i_nlinks;
unsigned short i_zone[9]; //实际数据所在的数据块磁盘块号
//取值范围为s_firstdatazone~s_firstdatazone+8192*8-1。
//如果是<7则用直接块号,否则使用间接,二次间接块号
}
- 数据区(data): 如果一个inode是dir,那么从i_zone指过来的数据块保存的是该dir下面包含的dir_entry,例如/usr/local/bin保留了., ..和java.exe三个文件。
#define NAME_LEN 14 //名字长度为14字节,这里的名字指的是usr,local等
#define ROOT_INO 1 //根节点号
struct dir_entry {
unsigned short inode; //dir对应的i节点号,1~8192*8-1
char name[NAME_LEN]; //该dir_entry对应的名字如usr, local等
};
如果inode是一个文件,那么从i_zone指过来的数据块保存的是文件内容。这里i_zone[9]里记录的是对应inode的磁盘块号,而不是逻辑块号nr。这两个之间有一个s_firstdatazone的差,即减去磁盘分区上的前几个块(引导块/超级快/i节点位图/逻辑块位图/i节点)。在超级块中s_firstdatazone记录了第一个数据块的磁盘号。所以,逻辑号和磁盘号之间有关系
block = nr + s_firstdatazone -1
1.2.从一个文件名寻找inode
这里的文件名形如/usr或者/bin/java.exe,目标是在磁盘文件系统上找到对应的inode信息。
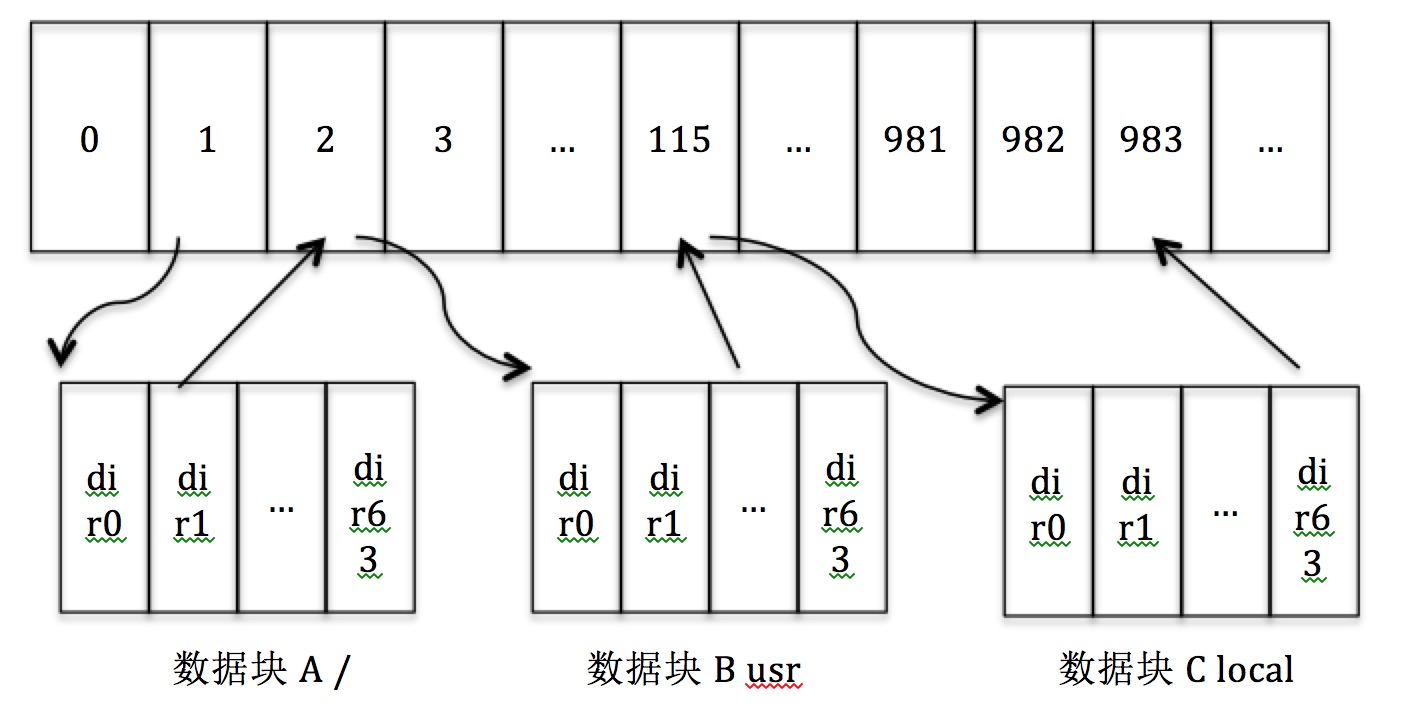
首先从根root /代表的inode开始(inode 1)找到/对应的i_zone,因为是/是一个dir,所以通过i_zone可以找到目录块内容,查到下面有/bin, /var, /usr等几个dir,找到/usr对应的inode,再从/usr代表的inode找到/usr下面对应的目录如/usr/local, /usr/bin等几个dir,找到/usr/bin对应的inode。在根据/usr/bin的inode找到其下对应的儿子节点,如果有java.exe则找到/usr/bin/java.exe对应的inode。
1.3.创建一个文件
目标是创建一个新文件wc.exe到/usr/local/bin下面
- 1)遍历zmap块找到可用使用的data block并置为1;
- 2)通过buffer将wc.exe写到data block中;
- 3)遍历imap块找到可用使用的inode并置1;
- 4)将wc.exe文件的数据如i_mode, mtime, i_uid等写入该inode;
- 5)找到其父亲节点/usr/local/bin的inode,随后找到对应的目录块数据,在目录块数据中加入新的一个dir entry数据,其中name为wc.exe,inode为wc.exe对应的inode号。这样该文件就关联到父亲节点上。
2.高速缓存
2.1.作用
高速缓存的作用是为了加速数据的读写,如果数据已经在高速缓存区,就不需要去读磁盘;当对数据进行写操作时,也可以先写到高速缓存区,然后由高速缓存模块统一写到硬盘上。高速缓存区分布从1M-4M。以1024为1个block,具体数目见buffer_init()函数。高速缓存区是以inode做为抽象层。
从用户进程来说,有两处数据需要用到高速缓存区。
- 用户进程本身的可执行代码文件(如/usr/bin/java)
- 用户进程通过系统调用write, read等从磁盘上读写指定文件。
对于第一种情况,首先是用户进程在fork之后通过exec调用,加载对应的可执行程序文件的inode,这时候根据文件名查找到inode信息,并对进程的线性地址空间进行分配,读取该inode对应的数据(参见进程调度一文关于exec的解释)。这个时候具体文件的内容还不会加载,只有到执行对应的代码,而代码对应的线性地址空间并不在内存中(查找页目录表和页表可知是否在内存中)时,缺页中断程序执行,从而会加载对应的可执行文件内容到高速缓存区中。
//程序执行exec
int do_execve(unsigned long * eip,long tmp,char * filename,
char ** argv, char ** envp){
...
if (!(inode=namei(filename))) /* get executables inode */
return -ENOENT;
...
//读出inode的开头4K数据
if (!(bh = bread(inode->i_dev,inode->i_zone[0]))) {
retval = -EACCES;
goto exec_error2;
}
...
}
//缺页处理, address为输入的线性地址
void do_no_page(unsigned long error_code,unsigned long address){
...
//第一个block空出来不用,所以block要从1开始算起
for (i=0 ; i<4 ; block++,i++)
nr[i] = bmap(inode,block);
//读出一页数据
bread_page(page,inode->i_dev,nr);
...
}
对于第二种情况,系统调用read, write会调用bread等操作完成inode的读写。
2.2.与其他模块的交互
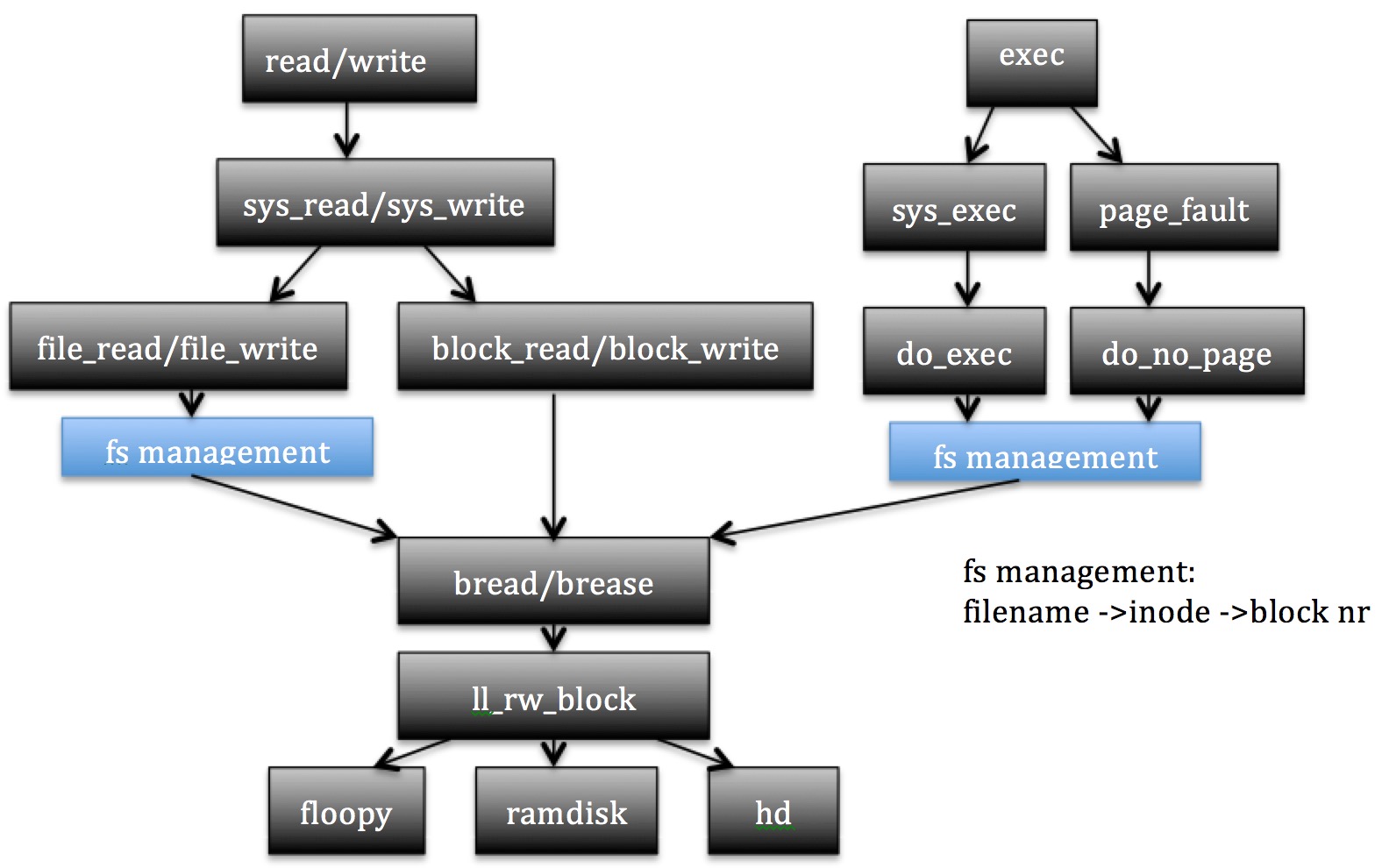
fs其他函数(do_exec,file_read, file_write)—> buffer bread( ) —> block dev ll_rw_block( ) —>硬盘控制器 —>硬盘
fs其他函数如do_exec, file_read等通过调用bread( int dev,int block)来读取block逻辑块的硬盘数据。
bread( )函数通过向block设备申请读入数据接口ll_rw_block( )来完成数据读写。
block设备具体通过和硬盘控制器发送指令读写数据。
2.3.实现
实现方面,使用了一个hash queue保存已经读到内存中的一个单位的blockd数据,hash queue一共307个主键,每个主键为dev^block_nr % 307。当hash_queue不止一个元素时组织成一个链表,另外使用了一个双向链表free_list保存所有可以使用的block。
初始化时,双向链表以free_list为头,hash table 307个键值对初始化为空。
申请数据时调用bread( )函数。
该函数首先根据请求的设备号和block_nr从hash queue里按主键值查找,如果发现已经数据已经在则直接返回;否则从free_list双向链表里从头开始寻找可以使用的块数据,寻找的规则是count=dirt=lock=0,如果没找到则休眠当前进程等待有空余的块数据可以使用。这里的休眠是因为高速缓存区域的内存是有限制的,没办法把所有硬盘数据刷入到内存中;当某个时刻所有的可以使用的高速缓存区都被任务占用(很多任务在读写不同的数据块),新的任务必须等待。
找到一个可以使用的空闲块以后,向块设备接口申请读入该block数据,将该buffer_head 根据其dev/block_nr的值加入到对应hash queue中,并且将该块数据从free_list其他位置 移到free_list双向链表的最后一项。最后一项表示这块内存是最后可以被使用的,因为搜索可以使用的空闲块时是从free_list的头往后寻找,所以最近使用的缓存数据在高速缓存中保存的时间最长,而最后使用的缓存数据在高速缓存中保存的实际时间最短(优先会被置换掉),这样就形成了最少访问优先使用的LRU (Least Recently Used)算法。
释放数据时调用brelse( )函数。该函数首先将对应的块数据应用计数-1,并且等待lock释放。这样在bread()检索时可以任务该块数据可以被使用。
比如说,在4分访问了2个块数据,加入到高速缓存中,之后释放掉;在5分又访问了另一块数据然后释放。4分得2个块数据会首先被置换出去,而5分的数据仍然会存在高速缓存中,直到4分的两个块数据读完,第3个数据读取请求到达。
用hash queue的目的是加速数据命中时检索和读取的速度。当然,我们也可以仅仅使用free_list,通过遍历free_list双向链表,找到可以使用的(count>=1)的块数据。这时候性能会大量损失。
3.block driver
block driver(块设备)提供读写接口,块设备的角色相当于是磁盘的抽象层,block driver可见的是设备号和数据块号。 上层模块通过block driver获取数据,对应模块的不同设备号是不相同的,例如swap的设备号是0,而高速缓存的设备号是3. 高速缓存读写操作和MM的交换分区操作都是通过block driver提供的函数完成操作的。
3.1.块设备读写模块承前继后的关系
MM模块的swap从硬盘读写数据
read_swap_page(swap_nr, (char * )page)
define read_swap_page(nr,buffer) ll_rw_page(READ,SWAP_DEV,(nr),(buffer));
对应关系为一个swap 页对应到8个sector(4096)
req->sector = page<<3; //swap_page<<3
req->nr_sectors = 8;
swap nr 0是一个特殊的swap页,其数据的最后10bit应该为”SWAP_SPACE"
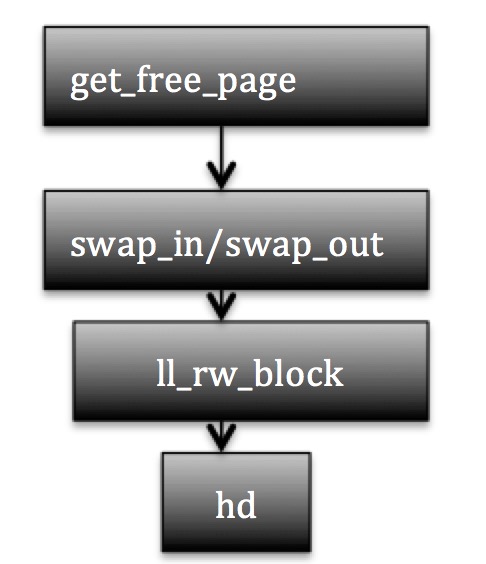
buffer模块从硬盘读写数据:
ll_rw_block(int rw, struct buffer_head * bh)
req->sector = bh->b_blocknr<<1;
req->nr_sectors = 2;
对应关系为一个block对应到2个sector (1024)
- block 1: sector 2 3
- block 2: sector 4 5
3.2.请求队列的竞争控制
在block device设备驱动层,每个设备对应一个请求队列,请求队列的每一项是一个数据块读写请求,根据电梯算法,将请求按照访问最优策略加入到请求队列中。这就涉及到一个问题,同时对相同设备的读写请求是如何处理的。实际上,在设备请求入队列的过程中,中断是关闭的,保持对队列的增加操作是原子性的。这里关闭中断 不仅对timer中断进行了屏蔽,更重要的是对磁盘控制器的中断请求进行了屏蔽。而后者,是需要访问当前请求队列的。实际上,timer中断如果不屏蔽,也只是对当前add_request的进程做一次时间计时而已,add_request还是会继续得以执行的。
static void add_request(struct blk_dev_struct * dev, struct request * req)
{
struct request * tmp;
req->next = NULL;
//关闭中断
cli();
if (req->bh)
req->bh->b_dirt = 0;
//当前设备没有请求,则将该请求加入,并直接执行request_fn
if (!(tmp = dev->current_request)) {
dev->current_request = req;
//这里打开中断
sti();
(dev->request_fn)();
return;
}
for ( ; tmp->next ; tmp=tmp->next) {
if (!req->bh)
if (tmp->next->bh)
break;
else
continue;
//如果tmp到req 或者 req到tmp->next
if ((IN_ORDER(tmp,req) ||
!IN_ORDER(tmp,tmp->next)) &&
IN_ORDER(req,tmp->next))
break;
}
//当前req放入requst链表
req->next=tmp->next;
tmp->next=req;
//这里打开中断
sti();
}
而当一个设备读写请求完成后,磁盘控制器的中断请求会引起取链表中的下一个请求。这里没有关闭中断,原因是这里取链表的下一个元素的操作,是在磁盘读写请求完成后的中断程序中执行的。试想如果在执行取链表元素下一个的时候,该中断程序被timer中断抢占,而timer中断会发现当前的进程代码已经运行在内核态,从而退出,使得取链表元素的操作得以继续执行。
#define CURRENT (blk_dev[MAJOR_NR].current_request)
/*结束块读写请求 唤醒等待在当前block rw上的任务*/
extern inline void end_request(int uptodate)
{
DEVICE_OFF(CURRENT->dev);
//解除block并唤醒等待该block的任务队列
if (CURRENT->bh) {
CURRENT->bh->b_uptodate = uptodate;
unlock_buffer(CURRENT->bh);
}
if (!uptodate) {
printk(DEVICE_NAME " I/O error\n\r");
printk("dev %04x, block %d\n\r",CURRENT->dev,
CURRENT->bh->b_blocknr);
}
//唤醒可能的swap等待任务,注意swap读写时会一直阻塞并且req.waiting= current。
wake_up(&CURRENT->waiting);
//唤醒等待加入block dev请求队列的任务
wake_up(&wait_for_request);
CURRENT->dev = -1;
CURRENT = CURRENT->next;
}
4.I/O调度
由于硬盘读写的速度是非常慢的,所以在讨论系统性能时I/O吞吐率以及相应的调度无疑是需要特别关注的。这里试图从linux0.12的实现角度回答一下几个问题:
- block I/O在CPU时间分配和执行上,是如何进行的。到底是哪个进程在负责读写I/O?
- 多个任务同时读写同一个文件的效率问题?多个任务同时读写不同文件的效率问题?是单任务读写快还是多个任务快?
- linux0.12有没有提供异步I/O?
假设有三个任务同时对某个inode进行写操作,当然我们假设对该inode的不同数据块,比如任务A写第一个数据块(1-1024),任务B写第二个数据块(1025-2048),以此类推。当然任务A开始写的时候假设他是对该硬盘设备的第一个请求,于是任务A发现请求队列为空,将自己的请求加入到队列头,并通过向控制器发送读写控制字然后休眠等待,于此同时任务B和任务C也开始写操作,在调度程序看来,此时任务A处于内核态休眠中(执行系统调用write中),任务B也陷入内核调用,将自己的第二个数据块的请求追加到请求对列;任务C类似也陷入内核调用,将自己的第三个数据块的请求追加到请求对列。三个磁盘操作的进程都陷入内核态休眠等待。
如果磁盘控制器将第一个块成功写入以后,控制器发出中断通知内核,内核通过hd_interrupt响应该中断,由于磁盘读写时将write_intr read_intr注册为回调函数(具体的做法是通过修改了do_hd函数的地址),这两个回调函数会继续查看队列是否还有读写请求,于是在中断处理函数中继续向控制器发出读写操作命令,该中断处理程序然后退出。注意,第一次磁盘读写中断处理是在另外一个正在运行的任务中(如系统init进程)抢占的。第一次磁盘读写任务完成后,任务A就被从内核态休眠中唤醒继续执行(write调用后面的代码得以继续执行)。
紧接着,磁盘控制器将第二个块成功写入,磁盘中断处理函数继续向控制器发出读写操作命令,该中断处理程序然后退出。这一次的磁盘读写中断处理是在另外一个正在运行的任务中(如被唤醒的进程A)抢占执行的,第二次磁盘读写任务完成后,任务B 就被从内核态休眠中换醒继续执行(write调用后面的代码得以继续执行)。
最后,磁盘控制器将第三个块成功写入,磁盘中断处理函数发现请求队列为空,不在向控制器发读写请求,该中断处理程序然后退出。这一次的磁盘读写中断处理还是在另外一个正在运行的任务中(如被唤醒的进程B)抢占执行的,第三次磁盘读写任务完成后,任务C 就被从内核态休眠中换醒继续执行(write调用后面的代码得以继续执行)。
可见,每次读写磁盘的等待时间是由控制器发起中断决定的,也就是磁盘马达读写磁盘的速度决定了磁盘读写的等待时间。所以针对I/O的优化最终要保证读写磁盘文件以一致有序的方式进行,比如读写大小为磁盘数据块大小512字节,读写的方向是按照磁盘号有序进行等待。这样保证读写文件的速度达到最高。
回到一开始的问题,
- block I/O在CPU时间分配和执行上,是如何进行的。到底是哪个进程在负责读写I/O?
A: 没有CPU时间消耗在I/O读写上,这句话的意思是I/O读写对内核而言,是一个离线的异步过程。内核将读写命令发送给控制器并注册中断回调函数以后,就算结束了。之后I/O的具体读写是由控制器本身控制磁盘驱动马达完成的。那么这里的block I/O又体现在哪里?具体而言,体现在内核休眠等待上,就是下面bread函数的wait_on_buffer上。
/*
* bread() reads a specified block and returns the buffer that contains
* it. It returns NULL if the block was unreadable.
*/
struct buffer_head * bread(int dev,int block)
{
struct buffer_head * bh;
if (!(bh=getblk(dev,block)))
panic("bread: getblk returned NULL\n");
//该block已经是最新的,直接返回
if (bh->b_uptodate)
return bh;
//该block不是最新,需要从硬盘中读取
ll_rw_block(READ,bh);
//在这里等待读操作结束
wait_on_buffer(bh);
if (bh->b_uptodate)
return bh;
brelse(bh);
return NULL;
}
- 多个任务同时读写同一个文件的效率问题?多个任务同时读写不同文件的效率问题?是单任务读写快还是多个任务快?
A: 实际上读写文件的速度和进程数目是没有多大关系的,所有的进程都会被阻塞在write系统调用上,而该调用主要完成的是将磁盘读写请求送入队列,然后等待磁盘控制器在读写任务完成后中断通知内核。所以,多个任务读写硬盘并不会比单个任务更快。增大进程数会对计算敏感的任务有效。 - linux0.12有没有提供异步I/O?
A: 有的。select调用就是。